A tale of Goblins and Streams
At QCon 2014, LinkedIn gave a talk (slides) about their Gobblin project (as well as published a blog post). Gobblin is a unified data ingestion system, aimed at providing Camus-like capabilities for sources other than Kafka. While Gobblin is a fascinating piece of engineering, what I find to be no less fascinating is the direction LinkedIn has chosen by going for a system like Gobbblin.
In "Putting Apache Kafka To Use: A Practical Guide to Building a Stream Data Platform", Jay Kreps describes his vision where Kafka becomes an organizational data hub, consolidating data from all kinds of sources.
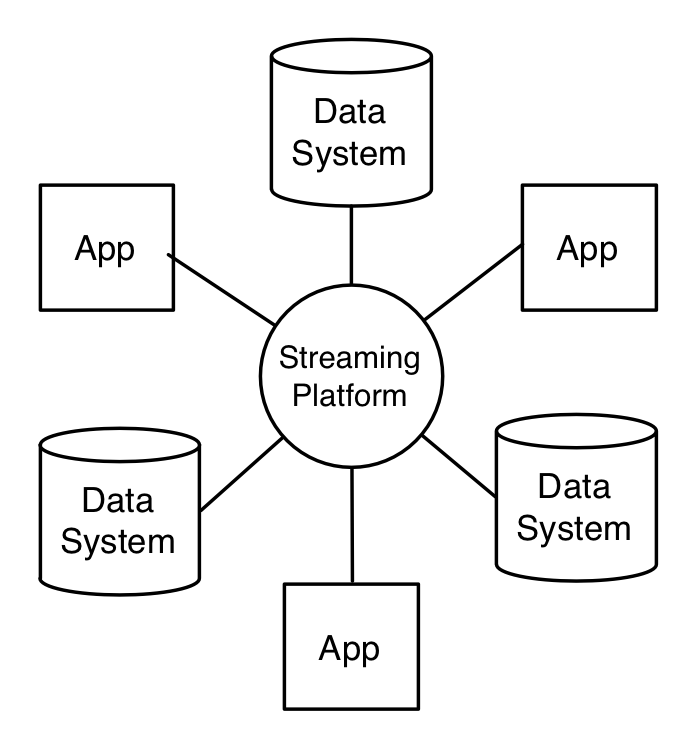
In "Putting Apache Kafka To Use: A Practical Guide to Building a Stream Data Platform", Jay Kreps describes his vision where Kafka becomes an organizational data hub, consolidating data from all kinds of sources.
| All data is reported to the streaming platform (Kafka) source: https://www.confluent.io/blog/event-streaming-platform-2/ |
In this vision, Kafka (not necessarily in the form of a single cluster) is the heart of a data stream platform that receives events from other systems, and acts as a central data hub where all data is made available for consumption, processing and more. Such an architecture would look like so:
 |
| Stream oriented ingestion pipeline |
Note that the ingestion backbone (Kafka-Camus-Hadoop), so to speak, does not change upon adding a new source, as long as it's publishing its data to Kafka. This architecture allows consumers to choose what tradeoffs they are willing to make. If they want freshness, possibly on the account of accuracy, they can consume data right off Kafka. If they want accuracy, (definitely) on the account freshness, they can read their data from Hadoop. Since consumers may come in all shapes and forms, providing them with the ability to wisely choose their consumption flow depending on their needs can be very beneficial.
A Gobblin centric architecture, on the other hand, is very source specific. That is, upon adding a new source, it must be accommodated in Gobblin by implementing the logic that dictates how data is to be extracted from that particular source in terms of the Gobblin API, so it can be ingested into Hadoop.
 |
| Gobblin oriented ingestion pipeline |
In such an architecture, Kafka acts as merely another source, and consequently, holds only a portion of the data. Hadoop becomes the only place where all data is to be found. This in turn, mandates consumers to go to Hadoop to get their data (unless they read it directly from the source, which is sort of a hack that defeats the purpose of designing a central data hub). This architecture seems to lack the flexibility previously described, where consumers have a certain degree of control over the tradeoffs between data freshness and accuracy.
Understanding the tradeoffs of a distributed architecture is crucial, and it remains interesting to see how both approaches evolve, and if either will prevail over time.


hi Stas,
ReplyDeleteNot sure if I agree with a couple of things on your blogpost
1) You say "That is, upon adding a new source, it must be accommodated in Gobblin by implementing the logic that dictates how data is to be extracted from that particular source in terms of the Gobblin API, so it can be ingested into Hadoop." - but this is not unique to Gobblin. In the Kafka-centric picture you still have to get the data from the source to Kafka so all this work needs to be done there too - just in terms of the Kafka API
2) There are sources that dont really fit into the log paradigm. For e.g. it is common to get a daily dump into a ftp site. These are usually copied directly into the object store (HDFS/S3 ) without going through Kafka.
3) Gobblin doesnt have to write to HDFS (or S3/GCS/..)- there is work happening to let it write to Kafka too . It will also write to (and read from) Kinesis, Azure Service Bus etc . So Gobblin can fit into your first picture both as the replacement for Camus and as a way of getting data into Kafka
I think where Gobblin shines is that it moves a small set of things (extract, simple transform, and load) into a single product that is source and destination agnostic. If you wanted to move your log transport from Kinesis to Kafka (or vice versa) or from HDFS to S3 you should be able to do it relatively cheaply
Hi anonymous,
ReplyDeleteThanks for the comment.
1) While not a unique constraint, at this point int time I believe Kafka is pretty much the de-facto standard for scalable real-time data feeds, and its API is by far the more common and mature one, when compared to Gobblin's API, which is definitely a point in favor of Kafka as I see it.
2) That's a valid point, once you already have the aggregated data and you "just" need to have it in Hadoop, Gobblin is indeed a nice solution.
3) Interesting, I was not aware of this (is this work being done by LinkedIn?). Currently Gobblin's mission statement on GitHub says "Gobblin is a universal ... and loading large volume of data from a variety of data sources onto Hadoop". It would be quite exciting to see it evolve into an even more generic tool. From what I've seen the fact Hadoop is the target storage is a pretty fundamental assumption in Gobblin's design, used to provide strong delivery guarantees (similarly to what Camus did). It will be interesting to see it circumvented.
No doubt Gobblin is an impressive piece of engineering, I just wonder how it fits best in the overall picture, which also has a great impact on its adoption. The beauty of Kafka is that it has become very common, and keeps getting more and more traction and features. Gobblin, on the other hand, plays in a very similar (if not the same) arena but needs plenty of stuff (e.g. "extractors" and "publishers") to be implemented in Goblinish, a brand new, non trivial model and API that needs to accommodate quite a few things before it becomes as universal as we'd like it to be.
Have you adopted Gobblin in your production (or any other) environment?
If so, I'd love to hear about your experience with it.